Tailing the MongoDB Oplog on Sharded Clusters with Scala and Akka Streams
- 5 minsIntroduction
This post is a continuation of the previously published post Tailing the MongoDB Replica Set Oplog with Scala and Akka Streams.
As it was discussed previously, tailing the MongoDB Oplog on Sharded Cluster have some pitfalls compared to the Replica Set. This post will try to cover some aspects of this topic and little bit more.
There are 2 really good articles, fully covering the topic of Tailing the MongoDB Oplog on Sharded Clusters from MongoDB team. You can find them here:
- Tailing the MongoDB Oplog on Sharded Clusters
- Pitfalls and Workarounds for Tailing the Oplog on a MongoDB Sharded Cluster
You can also find more information about the MongoDB Sharded Cluster in documentation hub.
The project built as an example is available on github.
The examples provided in this post shouldn’t be considered and used as production ready.
MongoDB Sharded Cluster
From MongoDB documentation:
Sharding, or horizontal scaling, by contrast, divides the data set and distributes the data over multiple servers, or shards. Each shard is an independent database, and collectively, the shards make up a single logical database.
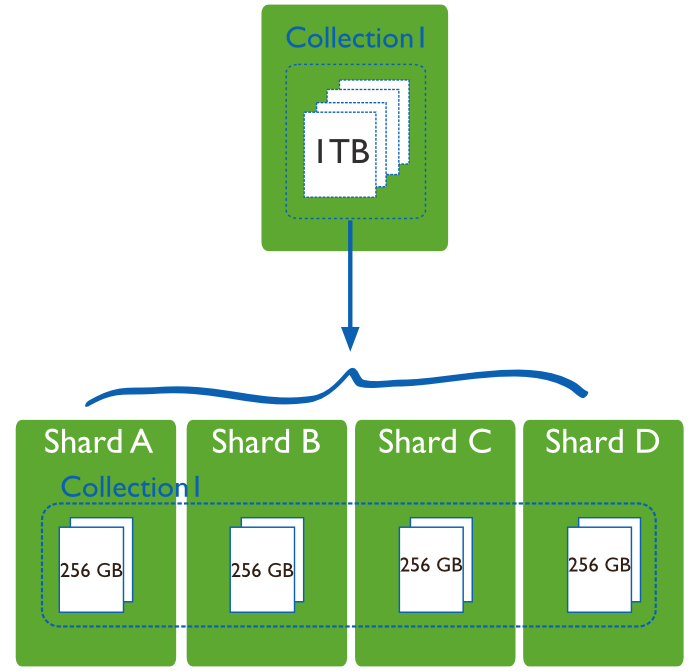
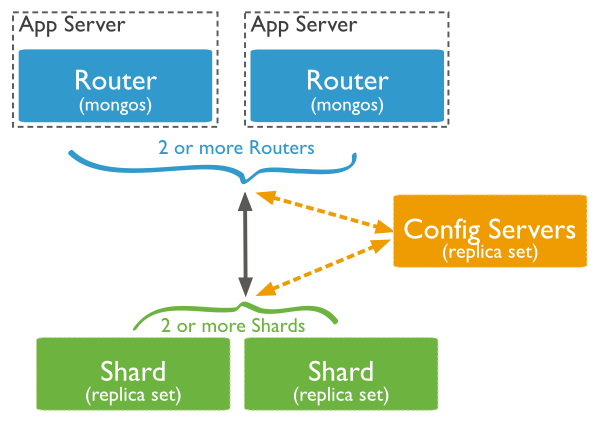
In production architecture each shard is represented by Replica Set:
MongoDB internal operations
Due to distribution of data on multiple nodes, MongoDB have cluster-internal operations, which are reflected in oplog. These documents have extra field fromMigrate, since we are not interested in these operations, we will update our oplog query to exclude them.
Retrieving Shard Information
As you might have guest already, to tail the Oplog on Sharded Cluster we should tail the Oplogs of each shard (Replica Sets).
To do so we can query the config database to get the list of available shards. The documents in the collection look something like:
I preferrer to use a case classes instead of Document objects, so I’ll define it:
case class Shard(name: String, uri: String)and the method to parse Document to Shard:
and now we can query the collection:
In the end, we will have the list of all shards in our MongoDB Sharded Cluster.
Defining the Source for each shard
To define the Source, we can simply iterate over the list of shards and use the same method, as in previous article, to define it per shard.
One Source to rule them all
We could process each Source separately, but of course it’s much easier and more comfortable to work with them as with single Source. To do so, we should merge them.
In Akka Streams there are multiple Fan-in operations:
- Merge[In] – (N inputs , 1 output) picks randomly from inputs pushing them one by one to its output
- MergePreferred[In] – like Merge but if elements are available on preferred port, it picks from it, otherwise randomly from others
- ZipWith[A,B,…,Out] – (N inputs, 1 output) which takes a function of N inputs that given a value for each input emits 1 output element
- Zip[A,B] – (2 inputs, 1 output) is a ZipWith specialised to zipping input streams of A and B into an (A,B) tuple stream
- Concat[A] – (2 inputs, 1 output) concatenates two streams (first consume one, then the second one)
We will use simplified API for Merge and then output the stream to STDOUT:
Error Handling - Failovers and rollbacks
For error handling Akka Streams use Supervision Strategies. There are 3 ways to handle errors:
- Stop - The stream is completed with failure.
- Resume - The element is dropped and the stream continues.
- Restart - The element is dropped and the stream continues after restarting the stage. Restarting a stage means that any accumulated state is cleared. This is typically performed by creating a new instance of the stage.
The default strategy is Stop.
But unfortunately it’s not applicable to ActorPublisher source and ActorSubscriber sink components, so in case of failovers and rollbacks our Source will not be able to recover properly.
There is already an issue opened on Github #19950, I hope it’ll be fixed soon.
As an alternative you could consider suggested in the article Pitfalls and Workarounds for Tailing the Oplog on a MongoDB Sharded Cluster approach.
Finally a completely different approach would be to tail the oplogs of a majority or even all nodes in a replica set. Since the pair of the
ts & hfields uniquely identifies each transaction, it is possible to easily merge the results from each oplog on the application side so that the “output” of the tailing thread are the events that have been returned by at least a majority of MongoDB nodes. In this approach you don’t need to care about whether a node is a primary or secondary, you just tail the oplog of all of them and all events that are returned by a majority of oplogs are considered valid. If you receive events that do not exist in a majority of the oplogs, such events are skipped and discarded.
I’ll try to implement this approach next.
Summary
We didn’t cover the topic of Updates to orphan documents in a sharded cluster, as in my case I’m interested in all operations and consider them as idempotent per _id field, so it doesn’t hurt.
As you can see, there are some aspects which are pretty easy to handle with Akka Streams and those which are not. In general, I have mixed impression about the library. It have a good ideas, leveraging the Akka Actors and moving it to the next level, but it feels raw. Personally I’ll stick with Akka Actors for now.

Timur Khamrakulov
Leader and Data-driven generalist, interested in Distributed Systems, Big Data and Augmented Reality